
The Whys and Hows of Web Scraping – A Lethal Weapon in Your Data Arsenal
Simply put, web scraping is the process of the extracting certain data fields from target websites in an automated manner to deliver data sets in clean and ready-to-use format. A web crawling program will automatically load multiple web pages from the website one by one, and extract data, as per the requirements. It can be either custom built for a specific website or can be configured to work with several different websites that follow similar structure.
The data extracted from the web can be saved locally and imported to database based on the structure for various business applications. Let’s now explore the importance of web data and the applications in the subsequent sections.
Why do businesses need to scrape web data?
Jennifer Belissent, Principal Analyst at Forrester has explained something called alternate data or alt-data beautifully:
We all want to know something others don’t know. People have long sought “local knowledge,” “the inside scoop” or “a heads up” – the restaurant not in the guidebook, the real version of the story, or some advanced warning. What they really want is an advantage over common knowledge – and the unique information source that delivers it. They’re looking for alternative data – or “alt-data.”
Now, web data is a major component of the alternate data ecosystem since this is the data that gets generated outside of your organization in an unstructured format (thanks to the rapidly evolving web technologies). There is no doubt that companies focused only on the internal data (e.g., customer transactions) are missing out on some of the valuable insights that can be generated from various alternative data. Hence, enterprises must use web data to bolster the internal data assets and extract valuable insights.
Apart from that considering the enormity of the web, we’re also frequently witnessing new solutions/services that are completely based on the applications of web data. After all, the web is the largest and perpetual source of data spanning across all the industries. Check out the following to understand some of the key applications of web data:
- Product manufacturers can extract the reviews published on various online platforms (e.g., ecommerce sites) to capture Voice of Customer, monitor campaign performance, manage online reputation and unveil consumer insights that can potentially aid important strategic decisions.
- Entrepreneurs can build new solutions by aggregating data from several websites and providing additional value/intelligence on top of the extracted data. This can be anything from price comparison sites and news feed compilation to AI-based job feed matching and airline tracking.
- Similarly, research and analytics companies can cater to any industry by getting the relevant data. For instance, some of clients who work in fashion intelligence field, acquire data from several ecommerce portals, blogs and social media sites to help their clients predict the upcoming trend throughout the year. Another example can be research agencies who work on labor trends — they capture millions of job listings posted on various job boards and company sites for analysis and reporting.
- Financial intelligence companies acquire data from company websites, social media (e.g., cash tagged tweets), news sites to facilitate equity research, trend analysis, governance and compliance.
- Various forms of competitive intelligence can be performed by creating a repository of competitors’ catalog covering product and pricing details. This helps in creating a solid competitive pricing strategy as per the business dynamics. Along with this, the job listings data posted by competitors also reveals a lot about the future direction of the company and the current strategy.
Apart from these, the other use of cases of web data cover fraud detection, regulatory management, building training data sets for machine learning algorithms, real-time data analysis and everything in between.
How to acquire enterprise-grade web data?
There are broadly three options when it comes to web data extraction:
- Do it yourself (DIY) tools
- In-house crawlers
- Managed services
So, how to select the correct data extraction methodology? Well, it depends on the use case. In order to get started with web data extraction, take into account the primary factors of web crawling and then covers 12 different narrowed-down parameters to help businesses arrive at the apt solution.
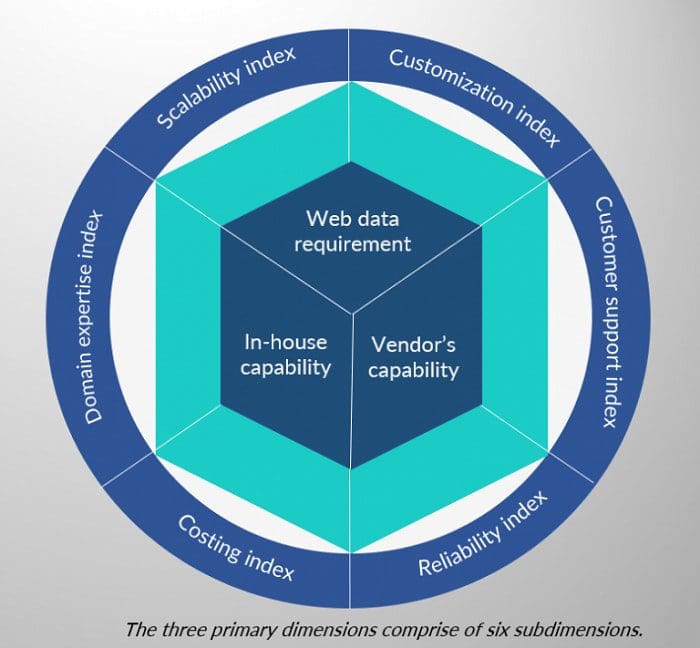
As a rule of thumb following set of questions need to be answered:
- Do you have a recurring (daily/weekly/monthly) web data requirement?
- Can you allocate a dedicated engineering team who can build the crawlers exactly as per your requirement and maintain it to ensure a steady flow of data?
- Will the volume significantly grow over time requiring a highly scalable data infrastructure?
If the answer to the first question is ‘no’, i.e., you require one-off data, then it is better to use a DIY tool. The learning curve initially can be high, but this option gives you a pre-built solution. Note that in case of high data volume that cannot be supported by a tool (even though it is a one-time requirement), the project can be outsourced to a managed service provider.
If the use case requires frequent web crawling and it is not possible to allocate dedicated resources for building a team to create a scalable data extraction infrastructure, you can engage with a fully managed web scraping service provider. The service provider would typically build custom web crawlers depending on the target site and deliver clean data sets exactly as per the requirement. It is also really important to ensure that the crawling service provider adheres to the guidelines specified in the robots.txt file and provides dedicated customer support team (with strong SLA) for the project.
This allows you to completely focus on the application of data without worrying about the data acquisition layer and maintenance. In-house web crawling gives you complete control on the project, but at the same time it requires skilled engineers to maintain the data feed at scale (read millions of records on daily or weekly basis). Note that dedicated engineering resources are a necessity since the websites change their structure frequently and the crawler must be updated to extract the exact data points without latency.
Over to you
We covered the important applications of web data along with some of the primary factors that one needs to consider while selecting data extraction solutions. As businesses around the globe move towards data-centric model, enterprises must look at customization options, scalability, pricing, dedicated service and delivery speed to leverage web data as an important data asset. This has the potential to directly impact the bottom line and grow market share.